Deploy a Rails App with Docker
This site is deployed using Docker containers on a small DigitalOcean Droplet.
Since I never have a private Docker registry, the original deploy flow was,
- push the source code to the remote Git repository
- on the Droplet, fetch the source code from the Git remote
- build an Docker image from the source code
- start the Docker container
Since some time ago, the docker build has kept failing on the bundle install instruction on the Droplet.
During bundle install, the Bundler fails to build the sassc gem.
The Bundler complains that,
virtual memory exhausted: Cannot allocate memory
, while building the sassc gem.
A workaround I tried was,
- build the Docker image on a more powerful machine, like the local dev machine
- save the image into a tar archive (
docker save img-foo | bzip2 > foo.img.bz) - copy the tar to the Droplet
- load the image from the tar (
bunzip2 foo.img.bz && docker load -i foo.img) - start the Docker container
One problem of the workaround was the volume to transfer is a bit large (the image is around 1G before compression, and 370M after compression). It was time consuming over a slow network.
Current Deploy Workflow
Actually, Bundler supports fetching gems from local cache, not only from rubygems.org.
Using bundle package --all can,
Copy all of the .gem files needed to run the application into the vendor/cache directory.
In the future, when running bundle install, use the gems in the cache in preference to the ones on rubygems.org.
The sassc gem is built on the local machine while bundle package, and put into vendor/cache directory.
Now, the deploy flow is like,
- run
bundle package --allif the application’s dependencies change - check in
vendor/cachefolder and push it to the Git remote - on the Droplet, fetch the source code from the Git remote
- build an Docker image from the source code
- start the Docker container
The Dockerfile is like,
USER app
RUN mkdir -p /home/app/source-code
WORKDIR /home/app/source-code
COPY vendor/cache ./vendor/cache/
COPY Gemfile* ./
# use RVM, so "bash -lc ..."
RUN bash -lc 'bundle install --deployment --without development test'
# copy the app source code
COPY . ./
Other Notes
If a gem is located at a particular git repository using the :git parameter, like
gem "rails", "2.3.8", :git => "https://github.com/rails/rails.git"
Then the --all option should be used in bundle package.
Some gems are built using CMake.
When run bundle package --all, CMakeCache.txt files are created and stored in vendor/cache.
The problem with CMakeCache.txt files is that they use hardcoded paths of the machine runs bundle package --all.
When build the Docker image in the remote server, the hardcoded paths fail the bundle install.
Therefore, in the .dockerignore file, add the following line.
vendor/cache/*/CMakeCache.txt
Java Generics, Bounded Wildcards and PECS
With a class hierarchy below,
class Fruit {
public void hello() {}
}
class Apple extends Fruit {}
class Banana extends Fruit {}
Lower Bounded Wildcards and Upper Bounded Wildcards
? super Fruit is called lower bounded wildcard.
? extends Fruit is called upper bounded wildcard.
Usually a class hierarchy is illustrated like,
Object
|
Fruit
/ \
Apple Banana
The base class is placed upper, subclasses placed lower.
For ? super Fruit, the lower bound of the type argument is determined, which is Fruit, so it’s called lower bounded wildcard.
Similar, for type argument ? extends Fruit, its upper bound is fixed, so it’s called upper bounded wildcard.
”? super Fruit”
void func(List<? super Fruit> fruits) {
fruits.add(new Fruit()); // ok
fruits.add(new Apple()); // ok
fruits.add(new Banana()); // ok
// Error: Cannot resolve method 'hello'
fruits.get(0).hello();
}
The ? in the declaration List<? super Fruit> means fruits is a List of an unknown type.
The ? super Fruit means the unknown type is limited to be Fruit or its super class (Object in this case).
When invoke func(List<? super Fruit> ), List<Fruit> or List<Object> can be passed as the argument.
All the fruits.add(...) in the above code is ok, because no matter what type actually the type argument is
Fruit, Apple, and Banana are the subtypes of that type.
An Apple object is a Fruit (or Object) object, so an Apple object can be added into a List of Fruit (or Object).
Why fruits.get(0).hello() fails?
The actual type of the elements in the fruits List is undetermined when declare the method.
When call a method on an element, the compiler needs to make sure the unknown type has the method.
? super Fruit in the type argument declaration sets bounds for the unknown type, one bound (“lower”) is type Fruit, the other bound (“upper”) is type Object
To safely invoke methods on the unknown type, only methods of the most upper type can be invoked.
Obviously, method hello is not from the most upper type (i.e. Object).
If passing a List<Object> as the parameter, then obviously the elements in fruits would not have hello() method. Therefore the compiler raises the error.
”? extends Fruit”
void func(List<? extends Fruit> fruits){
// Error: add(capture<? extends Fruit>) in List cannot be applied to add(Fruit)
fruits.add(new Fruit());
fruits.add(new Apple()); // similar error
fruits.add(new Banana()); // similar error
fruits.get(0).hello(); // ok
}
Similar, declaring the parameter as List<? extends Fruit> means fruits is an unknown type,
and can be List<Fruit>, List<Apple> or List<Banana> when the method is invoked.
Why fruits.get(0).hello() is ok in this case?
Similar, ? extends Fruit sets bounds for the unknown type, the upper bound is determined as the type Fruit.
The hello() method is from the most upper type, so the compiler knows it’s safe to call it within the func body.
Why statements like fruits.add(new Fruit()) fails?
The type of fruits is unknown, it doesn’t mean the type of fruits is “dynamic”.
Being “dynamic” means the type of fruits can be List<Fruit> at some point, then be List<Apple> at some other point.
It’s not possible in Java, since Java is a static language.
The two types, List<Fruit> and List<Apple>, have nothing to do with each other
(List<Apple> is not a subtype of List<Fruit>).
The type of the fruits parameter is determined on the invocation of func.
For a specific invocation, the type of fruits is determined and static.
For example, with an invocation like func(new ArrayList<Apple>()), the statement fruits.add(new Fruit()) would raise compiler error
(since a Fruit cannot be add()ed into a List<Apple>).
To ensure all the possible invocation of func works, the compiler just can’t allow the statements like fruits.add(new Fruit())
appear in the method body.
What is “capture” (capture<? extends Fruit>)?
"ssh" to a Windows Host
Every now and then, we may want to connect to a Windows host via ssh.
Maybe it’s due to the frustration on connecting a Windows host via Remote Desktop Connection over a slow network.
Below is a way to ssh (not really, actually) to a Windows host.
Step 0, install a Linux virtual machine in the Windows host
I use Oracle Virtual Box, and install a Ubuntu guest.
Step 1, share folders between the Windows host and the guest
Share the working folders between the Windows and the Ubuntu, so that these folders are accessible within the guest. Just google “virtualbox share folder”.
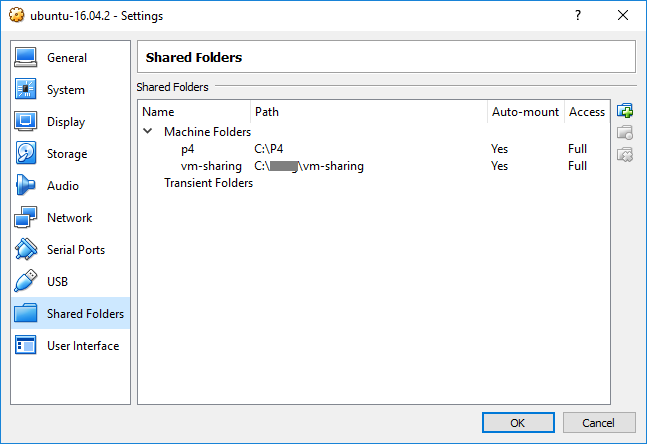
Step 2, configure the guest’s network settings
Choose NAT as the adapter type.
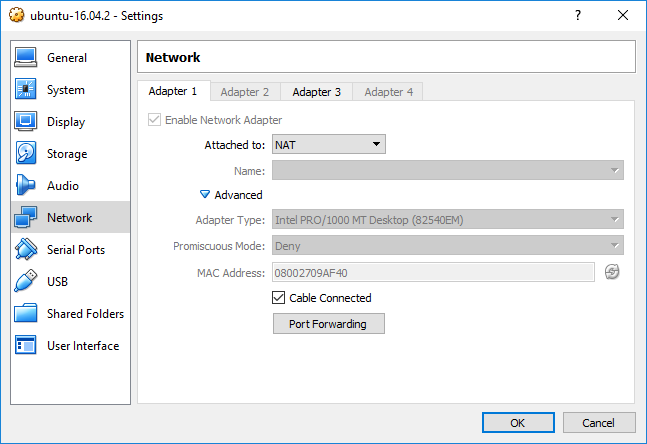
In the “Advanced” settings, add a port forwarding rule.
Choose an available port in the Windows host for “Host Port”.
Set “Guest Port” to 22, which is the default port sshd listening on in the Ubuntu guest.
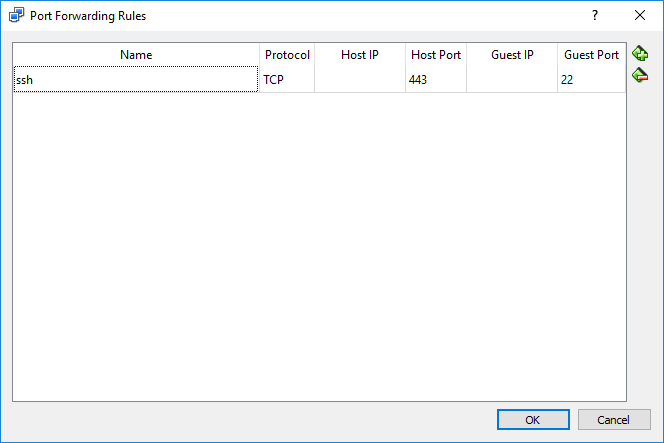
To find an available port in the Windows host, run netsh firewall show state in the cmd.exe.
In my corporate network, for example, port 443 is allowed.
Step 3, make a connection
Open a ssh client in another machine, type the IP (or host name) of the Windows host as the hostname,
use the “Host Port” as the port, 443 in my case, for the ssh connection.
# my_user is the username of the Ubuntu guest VM
# 1.2.3.4 is the IP of the Windows host
# 443 is the opened port in the WIndows host
ssh my_user@1.2.3.4 -p 443
# use the hostname of the Windows machine is also ok
ssh my_user@my_win_desktop.my_corp.com -p 443
After the connection is up, we’re in the Ubuntu VM. Change the directory to one of the shared folders set up in step 1, and do the work. Much better user experience than Windows Remote Desktop when the network is slow.
Other ways
One way is to set the adapter as “Bridged Adapter” for the Ubuntu guest, so that the guest get an IP from the corporate network. Configure the port of sshd to a port the corporate network allows to connect from outside. One inconvenience is that sometimes the corporate network may assign a new IP for the guest after reboot.
Another way is to install the OpenSSH Server directly in the Windows host.
Daily Dev Log: "--help" vs. "man"
We just can’t remember options of CLI tools.
In most cases, --help, like grep --help, is the go-to way to look for help.
For example, if you forget what -H of grep does.
$ grep --help | grep -- -H
-H, --with-filename print the file name for each match
man is too formal, wordy and overwhelming, comparing with --help.
Usually, we can find out most of what we want in the output of --help, without turning to man.
In some environments, man pages may not be available there. One such example is Git Bash for Windows.
Commands in Git Bash for Windows don’t have man pages.
Relying on man only means you have to google the man(ual) in the browsers.
To save some typing, a bash function can also be added into the ~/.bashrc.
h() { $1 --help; }
Then type h grep to show the help.
Note that different commands or different variants of a command may print help text in different verbosity.
For example, the builtin grep in OS X prints help text like below.
$ grep --help
usage: grep [-abcDEFGHhIiJLlmnOoqRSsUVvwxZ] [-A num] [-B num] [-C[num]]
[-e pattern] [-f file] [--binary-files=value] [--color=when]
[--context[=num]] [--directories=action] [--label] [--line-buffered]
[--null] [pattern] [file ...]
It’s much less than the Linux grep’s help text.
(Most of CLI tools support this level of help text at least.)
xargs is Slow
# filepaths.txt is a file with thousands lines
cat filepaths.txt | xargs -n 1 basename
It takes a while (seconds) to finish running the above command. A file with thousands lines usually is not considered as a big volume. Why is xargs slow in the above command?
After read a SO post, it turns out xargs in the above command runs basename thousands times,
therefore it has bad performance.
Can it be faster?
According to man xargs,
xargs reads items from the standard input … delimited by blanks … or newlines and executes the command … followed by items read from standard input. The command line for command is built up until it reaches a system-defined limit (unless the -n and -L options are used). … In general, there will be many fewer invocations of command than there were items in the input.
This will normally have significant performance benefits.
It means xargs can pass a batch of “items” to the command.
Unfortunately, the -n 1 option in the command forces xargs to just take one “item” a time.
To make it fast, use the -a option of basename, which let basename be able to handle multiple arguments at once.
time cat filepaths.txt | xargs -n 1 basename > /dev/null
real 0m2.409s
user 0m0.044s
sys 0m0.332s
time cat filepaths.txt | xargs basename -a > /dev/null
real 0m0.004s
user 0m0.000s
sys 0m0.000s
Thousands times faster.
–show-limits
cat /dev/null | xargs --show-limits --no-run-if-empty
Your environment variables take up 2027 bytes
POSIX upper limit on argument length (this system): 2093077
POSIX smallest allowable upper limit on argument length (all systems): 4096
Maximum length of command we could actually use: 2091050
Size of command buffer we are actually using: 131072
Maximum parallelism (--max-procs must be no greater): 2147483647
It shows xargs can feed a lot bytes into the command once (2091050 bytes here).
-P
Some commands can usefully be executed in parallel too; see the -P option.
Fix an Escaped Hyperlink Bug
There was a bug in timeline page.
Hyperlinks (<a>) were unwanted escaped, showed in the page like below.
if a feedback is submitted in <a href="/about">About</a> page, ...
The fix is rather simple as below.
- <li><%= p %></li>
+ <li><%= p.html_safe %></li>
Basically, html_safe tells rails not to HTML escape a string by claiming the string is “safe”
(doing nothing on the string but setting a flag).
html_safe should not be called on any user input strings, otherwise you’ll be under risk of XSS attacks.
For this site, the fix is safe since all the content in the timeline page is solely input by myself,
not by other malicious users.
More about html_safe
html_safe is a method of SafeBuffer, which is a String wrapper designed to prevent XSS attack.
SafeBuffer is almost the same as String, beside having a difference behavior on concatenation.
When a “safe” SafeBuffer A is appended by an “unsafe” SafeBuffer or String B, B will be HTML
escaped before concatenation. By default a SafeBuffer/String is not marked safe.
Rails uses SafeBuffer to prevent XSS attack. For the below erb,
<li><%= p %></li>
Rails translates it into something like,
'<li>'.html_safe + p + '<li>'.html_safe
Therefore, p, which may be from user input, is HTML escaped when concatenated, and rendered safely in the result page.
More than One Way in Ruby
Using raw has the same effect, but show the intention in a much clearer way.
<li><%= raw p %></li>
And one more, <%== is equivalent to raw, in case you really want to save some keystrokes.
will_paginate with Bootstrap
will_paginate doesn’t come with Bootstrap style pagination by default.
However, as its doc says, it does support customization by providing your
own LinkRenderer.
to customize HTML output of will_paginate, you’ll need to subclass WillPaginate::ActionView::LinkRenderer
Below is a simple implementation to render pagination links with Bootstrap(4) css components.
# app/helpers/application_helper.rb
module ApplicationHelper
def will_paginate(collection_or_options = nil, options = {})
if collection_or_options.is_a? Hash
options, collection_or_options = collection_or_options, nil
end
unless options[:renderer]
options = options.merge :renderer => BootstrapRenderer
end
super *[collection_or_options, options].compact
end
class BootstrapRenderer < WillPaginate::ActionView::LinkRenderer
protected
def html_container(html)
tag :nav, tag(:ul, html, class: "pagination pagination-sm"), container_attributes
end
def page_number(page)
tag :li, link(page, page, rel: rel_value(page), class: 'page-link'),
class: (page == current_page ? 'page-item active': 'page-item')
end
def previous_or_next_page(page, text, classname)
tag :li, link(text, page || '#', class: 'page-link'),
class: ['page-item', classname, ('disabled' unless page)].join(' ')
end
end
end
# app/views/posts/index.html.erb
# use 'text-center' to center inline-blocks (<ul>) within <nav>
<%= will_paginate @posts, params: @will_paginate_params, class: 'text-center' %>
Daily Dev Log: "su - app" vs. "su app"
From man su,
-, -l, --login Provide an environment similar to what the user would expect had the user logged in directly.
So with su - app, after switch to the user app, you end up in the user’s HOME directory,
and have the user’s ~/.bash_profile (not ~/.bashrc) executed.
Tools like RVM need a “login shell”.
RVM by default adds itself currently to ~/.bash_profile file
So if use su app, RVM will not be ready there for you after su.
Daily Dev Log: Avoid the Pitfall of Using the Same File to Redirect Input and Output
Pitfalls
Do Not Use the Same File to Redirect Input and Output
tr -d '\015' <DOS-file >DOS-file
The above command will delete all content in the file!
From man bash,
[n]>word, if it does exist it is truncated to zero size.
(How did I find the file back? Luckily, the working directory is managed by Dropbox, and I found it back in the Dropbox.)
CLI
Convert Line Endings from DOS/Windows Style to Unix/Linux Style
tr -d '\015' <DOS-file >UNIX-file
(For what character \015 is, see man 7 ascii or ascii '\015' if the ascii command is installed.)
More ascii Command Examples
$ ascii '\r'
ASCII 0/13 is decimal 013, hex 0d, octal 015, bits 00001101: called ^M, CR
Official name: Carriage Return
C escape: '\r'
Other names:
Search Manuals
-k Search the short descriptions and manual page names for the keyword
$ man -k ascii
ascii (1) - report character aliases
ascii (7) - ASCII character set encoded in octal, decimal, and hexadecimal
...
Fix a Maven Dependency Conflict
The Dependency Conflict Cannot be Resolved
A project I work on is using both “com.google.sitebricks:sitebricks”, a now inactively under development web framework, and “org.drools:drools-compiler” as its dependencies, both of which then depend on “org.mvel:mvel2”. Maven used to find a version of mvel2 to satisfy both of the two dependencies.
However, when the “drools-compiler” dependency is upgraded to a newest version (“7.13.0.Final”), something unfortunate happens. The “drools-compiler:7.13.0.Final” uses a mvel2 version, which is incompatible with the one sitebricks uses. The “drools-compiler” uses some new APIs from the newer version of mvel2, unfortunately, that version of mvel2 deletes some APIs “sitebricks” uses. In this case, Maven cannot resolve the dependency conflict easily since there is NO version of mvel2 to satisfy “drools-compiler:7.13.0.Final” and “sitebricks:*”.
A Fix
Use Maven Shade Plugin to package sitebricks and its mvel2 dependency into a “shaded jar”, and also use this plugin to “relocate” mvel2 classes inside the “shaded jar”. “Relocation” here is to move mvel2 classes from package “org.mvel2” to some other package like “org.shaded.mvel2”, and to also modify bytecode of some sitebricks classes, which refers mvel2 classes, correspondingly, so that these “mvel2 classes” do not conflict with those used by “drools-compiler”.
Create a Maven project/module for the “shaded jar”.
<artifactId>sitebricks-shaded</artifactId>
<packaging>jar</packaging>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<finalName>sitebricks-shaded-${project.version}</finalName>
<relocations>
<relocation>
<pattern>org.mvel2</pattern>
<shadedPattern>org.shaded.mvel2</shadedPattern>
</relocation>
</relocations>
<artifactSet>
<includes>
<include>org.mvel:mvel2</include>
<include>com.google.sitebricks:*</include>
</includes>
</artifactSet>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>com.google.sitebricks</groupId>
<artifactId>sitebricks</artifactId>
</dependency>
</dependencies>
In the project, use the “sitebricks-shaded” as a dependency instead.
<dependency>
<groupId>com.foo.bar</groupId>
<artifactId>sitebricks-shaded</artifactId>
<version>${project.version}</version>
</dependency>
<dependency>
<groupId>org.drools</groupId>
<artifactId>drools-compiler</artifactId>
<version>${drools.version}</version>
</dependency>
And one more step.