Different Emails Addresses for Different Git Repositories
Sometimes, we may want to set up different user emails and user names for different Git repositories.
For example, in your personal computer, the user.email is set to your personal email address globally.
While committing to your corporate repositories in the personal computer, your corporate email address should be used in the
commits. Or you’re working on personal projects on the corporate computer, need to use the personal email for the personal
repositories.
Configure Email Address for A Repository
The simplest way is going to each repository, and configuring the user email for each repository specifically.
$ cd /path/to/repo-foo
$ git config user.email email.foo@example.com
$ git config user.name name-foo
The above git config commands write the user.email setting into the .git/config file under the repository.
From git help config, when writing configuration, by default it’s writing to the repository-local configuration file.
When writing, the new value is written to the repository local configuration file by default, and options –system, –global, –worktree, –file
can be used to tell the command to write to that location
Examine the Email Address for a Repository
$ cd /path/to/repo-foo
$ git config --list | grep user.email
user.email=email.bar@example.com
user.email=email.foo@example.com
The git config --list above prints more than one user.email values. It’s because, without additional options, the
git config --list outputs configuration “merged” from system, global and local.
From git help config,
When reading, the values are read from the system, global and repository local configuration files by default
The git config --list is a read operation.
The first user.email value above is from “global”, i.e. ~/.gitconfig.
Run git config --list --local | grep user.email to check the repository-local email configuration.
Instead of piping config --list and grep, use git config --get user.email to save some typings.
$ cd /path/to/repo-foo
$ git config --get user.email
user.email=email.foo@example.com
From git help config, --get returns
the last value if multiple key values were found.
Here, the last value is the email from repository-local configuration.
The --get can be further omitted, git config user.email has the same result.
And git config --get-all user.email is same as git config --list | grep user.email.
Conditional Includes
For new cloned repositories, it’s often to forget to configure the right email addresses for them.
The “conditional includes” feature of the git config can save us from this problem.
For example, in your personal computer, all corporate repositories are under ~/corp-repo/.
Add a text file called corp-gitconfig there, and edit it as below.
[user]
name = user-name-for-corp-prj
email = email-add@your-corp.com
Add below lines in the global git config file, i.e. ~/.gitconfig.
[includeIf "gitdir:~/corp-repo/"]
path = ~/corp-repo/corp-gitconfig
Now if a new repository is cloned user ~/corp-repo/, the email for that repository is automatically set to
email-add@your-corp.com.
Sort .csv Files by Columns in Command Line
The sort command can be used to sort .csv files by specific columns.
Have an example .csv file like below.
$ cat orders.csv
user,date,product,amount,unit price
user-2,2020-05-11,product-2,2,500
user-3,2020-04-11,product-1,2,600
user-1,2020-06-11,product-3,2,100
user-1,2020-06-21,product-1,6,600
user-1,2020-04-12,product-3,2,100
To sort orders by highest unit price, run the command below.
$ sort -r --field-separator=',' --key=5 -n orders.csv
user-3,2020-04-11,product-1,2,600
user-1,2020-06-21,product-1,6,600
user-2,2020-05-11,product-2,2,500
user-1,2020-06-11,product-3,2,100
user-1,2020-04-12,product-3,2,100
user,date,product,amount,unit price
The --field-separator option (or -t) specifies , as the field separator character. By default, sort considers
blank space as the field separator character.
The --key=5 let sort use the fifth field of lines to sort the lines.
The -n is to sort numerically, and -r is to sort in reverse order.
To fix the headers of the .csv file at the very first row after sorting, process substitution can be used.
$ cat <(head -1 orders.csv) \
<(tail -n +2 orders.csv|sort -r --field-separator=',' --key=5 -n)
user,date,product,amount,unit price
user-3,2020-04-11,product-1,2,600
user-1,2020-06-21,product-1,6,600
user-2,2020-05-11,product-2,2,500
user-1,2020-06-11,product-3,2,100
user-1,2020-04-12,product-3,2,100
To sort orders by highest unit price and amount, provide multiple --key options as below.
$ cat <(head -1 orders.csv) \
<(tail -n +2 orders.csv|sort -r -t ',' -k 5 -k 4 -n)
user,date,product,amount,unit price
user-1,2020-06-21,product-1,6,600
user-3,2020-04-11,product-1,2,600
user-2,2020-05-11,product-2,2,500
user-1,2020-06-11,product-3,2,100
user-1,2020-04-12,product-3,2,100
The format of value of --field-separator could be a bit more complex.
For example, to sort orders by the day of order date, run the command below.
$ sort -t , -n -k 2.9 orders.csv
user,date,product,amount,unit price
user-1,2020-06-11,product-3,2,100
user-2,2020-05-11,product-2,2,500
user-3,2020-04-11,product-1,2,600
user-1,2020-04-12,product-3,2,100
user-1,2020-06-21,product-1,6,600
The -k 2.9 means for each line sort uses strings which starts from the ninth position of the second field till the end of the line.
The -k 2.9,5 means for each line sort only looks at strings which starts from the ninth position of the second field and ends at the last character
of the fifth field.
The -k 2.9,5.2 means sort only looks at strings which starts from the ninth position of the second field and ends at the second character
of the fifth field.
For more details, check the man sort.
Find a Tab in Hundreds of Tabs of Dozens of Safari Windows
When use Safari in my Mac, I often keep hundreds of tabs open in dozens of Safari windows.
For a recently working on tab, I may remember which Safari window it’s in, and switch to that window by looking at
the snapshots of all windows brought up by Ctrl + Down arrow.
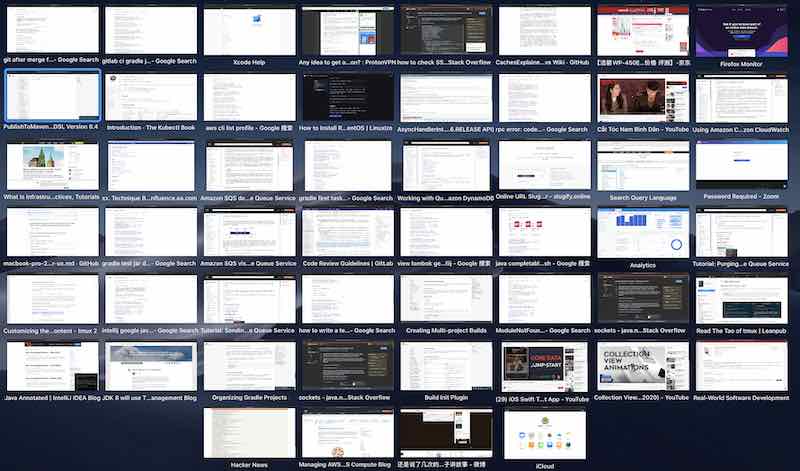
To locate a tab which I totally forget where is it in, it can be easily found via the menu bar -> Help -> Search. Type the keywords of that tab in the input box.
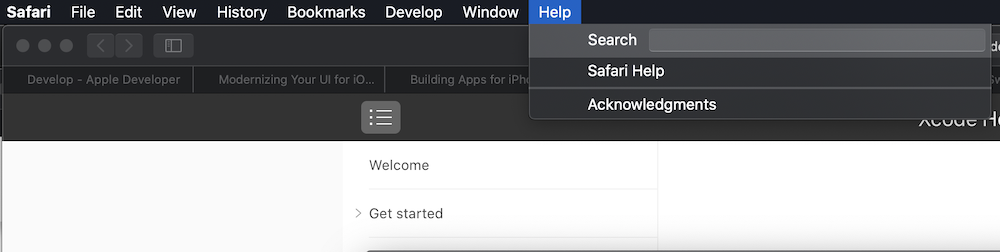
If you know which Safari window a tab is in, click the “double square” icon in the upper-right corner of the window (or View -> Show Tab Overview).
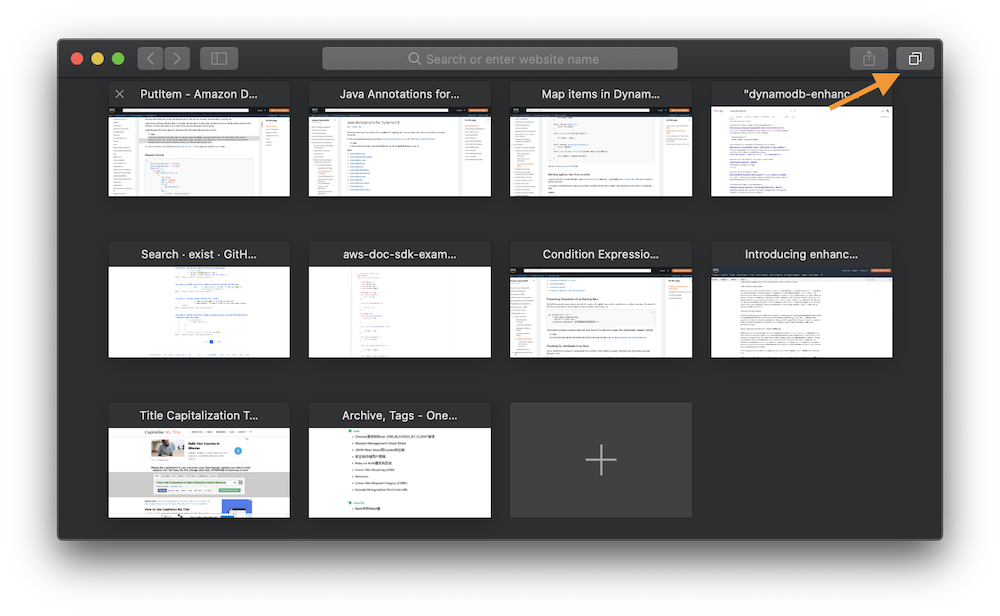
Then type some keywords of the tab to narrow down the matched result.
Jackson Mix-in Annotations
Jackson has a feature called Mix-in annotations. With this feature, we can write cleaner code for the domain classes. Imagine we have domain classes like below.
// package com.example
public interface Item {
ItemType getType();
}
@Value
public class FooItem implements Item{
@NonNull String fooId;
@Override
public ItemType getType() {
return ItemType.FOO;
}
}
When implement these domain classes, no Jackson annotation is put on them.
To support serialization and deserialization with Jackson for these classes, add “Mix-in” classes, for example in a
separate package called com.example.jackson.
Add ItemMixin below to let Jackson be able to serialize and deserialize Item and its subclasses.
@JsonTypeInfo(
use = JsonTypeInfo.Id.NAME,
include = JsonTypeInfo.As.PROPERTY,
property = "type")
@JsonSubTypes({
@JsonSubTypes.Type(value = FooItem.class, name = "FOO")
// ...
})
public abstract class ItemMixin {
}
// merge the Jackson annotations in the Mix-in class into the Item class,
// as if these annotations are in the Item class
objectMapper.addMixIn(Item.class, ItemMixin.class);
String json = "[{\"fooId\": \"1\", \"type\": \"FOO\"}]";
List<Item> items = mapper.readValue(json, new TypeReference<List<Item>>(){});
Note that FooItem is implemented as an immutable class using @Value from Lombok.
With @Value annotated, FooItem has no default constructor, which makes Jackson unable to serialize it by default.
Add FooItemMixin below to fix it.
@JsonIgnoreProperties(value={"type"}, allowGetters=true)
abstract class FooItemMixin {
@JsonCreator
public FooItemMixin(@JsonProperty("fooId") String fooId) {
}
}
With help of Mix-in annotations, the domain classes don’t have to be compromised for Jackson support. All Jackson relevant annotations are in separate Mix-in classes in a separate package. Further, we could provide a simple Jackson module like below.
@Slf4j
public class MixinModule extends SimpleModule {
@Override
public void setupModule(SetupContext context) {
context.setMixInAnnotations(Item.class, ItemMixin.class);
context.setMixInAnnotations(FooItem.class, FooItemMixin.class);
log.info("module set up");
}
}
The consumers of the domain classes can simple register this module to take in all the Mix-in annotations.
objectMapper.registerModule(new MixinModule());
Jackson Mix-in helps especially if the domain classes are from a third party library. In this case, the source of the domain classes cannot be modified, using Mix-in is more elegant than writing custom serializers and deserializers.
Which Accessor Style? "Fluent" vs. "Java Bean"
Basically, there are two styles of accessor naming convention in Java.
One is the traditional “Java Bean” style.
public class Item {
ItemType getType();
}
Another is called the “fluent” style.
public class Item {
ItemType type();
}
The fluent style saves some typing when writing code, also makes code a bit less verbose, item.type().
For example, the Lombok library supports this fluent style.
lombok.accessors.fluent = [true | false](default: false)
If set to true, generated getters and setters will not be prefixed with the bean-standard ‘get, is or set; instead, the methods will use the same name as the field (minus prefixes).
Which style is better?
Actually, the verbose Java Bean style, is the better one.
It’s because a lot of third party libraries are acknowledging the Java Bean style.
For example, if Item is going to be serialized by the Jackson library as a JSON string, the fluent style wouldn’t
work out of the box.
Also, most of DTO mapping libraries are using the Java Bean style too.
Therefore, using the standard Java Bean accessor style save effort when integrate our classes with other libraries and frameworks.
With the Lombok library and the auto-completion in modern IDEs, the Java Bean style doesn’t necessarily mean more typing.
The contains() Method in Java Collection Is Not "Type Safe"
Currency currency;
//...
if(currency.getSupportedCountries().contains(country)) {
//...
}
The Currency.getSupportedCountries() returns a Collection. Originally, the returned Collection was Collection<Country>.
The country object in the above if-condition was of type Country. The program has been well tested and worked as expected.
However, due to whatever reason, the getSupportedCountries() is refactored to return a Collection<String>.
The Java compiler complains nothing about the refactor. But the if-condition now is never true in any cases, since
the equals() method of String has no idea about the equality with Country and vice versa.
A bug!
It’s hard to detect this kind of bug, if the code is not well covered by unit tests or end-to-end tests.
In this sense, the contains() method in Java Collection is not type safe.
How to Avoid
First, never change the behavior of an API when refactor.
In the above case, the signature of the getSupportedCountries() API has changed.
This is a breaking change, which usually causes the client code fails to compile.
Unfortunately, in above case the client code doesn’t fail fast in the compile phase.
It’s better to add new API like getSupportedCountryCodes() which returns a Collection<String>, and @Deprecated
the old API, which can be further deleted some time later.
Second, make code fully covered by test cases as much as possible. Test cases can detect the bug earlier in the test phase.
Why contains() Is Not Generic
Why contains() is not designed as contains(E o), but as contains(Object o)?
There are already some discussion on this design in StackOverflow, like this one
and this one.
It’s said it’s no harm to let methods like contains() in Collection be no generic.
Being no generic, the contains() can accept a parameter of another type, which is seen as a “flexible” design.
However, the above case shows that this design does have harm and cannot give developers enough confidence.
A method accepting a parameter of Object means it accepting any type, which is too “dynamic” for a “static” language.
Another question is why a static language needs a “root” Object?
Run Multiple Gradle Sub Project Tasks
Use the brace expansion mechanism of Bash, multiple sub project tasks can be run in the command line like below.
$ ./gradlew sub-prj-1:{tasks,help}
After brace expansion, it is same as below, but saves some typing.
$ ./gradlew sub-prj-1:tasks sub-prj-1:help
More examples.
$ ./gradlew sub-prj-{1,2}:test
# same as
# ./gradlew sub-prj-1:test sub-prj-2:test
$ ./gradlew sub-prj-{1,2}:{clean,build}
# same as
# ./gradlew sub-prj-1:clean sub-prj-1:build sub-prj-2:clean sub-prj-2:build
The if-else Control Flow Using Optional
Sometimes you may want to write the if-else control flow based on an Optional object.
For example, an API from a third party library declares Optional as its return type.
You need to compose an if-else like control flow using that Optional object.
Of course, it can be done by testing isPresent() in a traditional if-else statement.
var itemOpt = service.getItem(itemId);
if (itemOpt.isPresent()) {
addToOrder(itemOpt.get());
} else {
log.info("missing item {}", itemId);
sendOutItemMissedEvent();
}
The above code doesn’t take any advantage of Optional.
Actually, since Java 9 the ifPresentOrElse(Consumer<? super T>, Runnable)
method can be used to implement such control flow, which is a bit more elegant.
service.getItem(itemId).ifPresentOrElse(
item -> {
addToOrder(item);
},
() -> {
log.info("missing item {}", itemId);
sendOutItemMissedEvent();
});
Print Exception Together With Parameterized Log Messages
Often when use SLF4J, you may wonder if an exception object can be printed in the same parameterized log message together with other objects. Actually SLF4J supports it since 1.6.0.
log.error("failed to add item {}", "item-id-1", new RuntimeException("failed to add item"));
The SLF4J call above prints log message like below.
13:47:16.119 [main] ERROR example.TmpTest - failed to add item item-id-1
java.lang.RuntimeException: failed to add item
at example.TmpTest.logErrorTest(TmpTest.java:10)
...
...
So it actually doesn’t need to log as below.
log.error("failed to add item {}", "item-id-1");
log.error("exception details:", new RuntimeException("failed to add item"));
Here is what the official FAQ says.
The SLF4J API supports parametrization in the presence of an exception, assuming the exception is the last parameter.
Use the first style to save one line.
SLF4J doesn’t clearly state this behavior in the Javadoc of Logger.error(String format, Object... arguments)
(at least not in the 1.7.26 version). Maybe if a new method like below is added to Logger, programmer would
find out this feature more easily.
public void error(String format, Throwable t, Object... arguments);
Process Substitution
From man bash, for “process substitution” it says
It takes the form of <(list) or >(list)
Note: there is no space between < or > and (.
Also, it says,
The process list is run with its input or output connected to a FIFO or some file in /dev/fd. The name of this file is passed as an argument to the current command as the result of the expansion.
The <(list) Form
$ diff <(echo a) <(echo b)
1c1
< a
---
> b
Usually the diff takes two files and compares them.
The process substitution here, <(echo a), creates a file in /dev/fd, for example /dev/fd/63.
The stdout of echo a command is connected to /dev/fd/63.
Meanwhile, /dev/fd/63 is used as an input file/parameter of diff command.
Similar for <(echo b).
After Bash does the substitution, the command is like diff /dev/fd/63 /dev/fd/64.
In diff’s point of view, it just compares two normal files.
In this example, one advantage of process substitution is eliminating the need of temporary files, like
$ echo a > tmp.a && echo b > tmp.b \
&& diff tmp.a tmp.b \
&& rm tmp.{a,b}
The >(list) Form
$ echo . | tee >(ls)
Similar, Bash creates a file in /dev/fd when it sees >(ls).
Again, let’s say the file is /dev/fd/63.
Bash connects /dev/fd/63 with stdin of ls command, also the file /dev/fd/63 is used as a parameter of
tee command.
The tee views /dev/fd/63 as a normal file.
tee writes content, here is ., into the file, and the content will “pipe” into the stdin of ls.
Compare with Pipe
Pipe, cmd-a | cmd-b, basically just passes stdout of the command on the left to the stdin of the command on the right.
Its data flow is restricted, which is from left to right.
Process substitution has more freedom.
# use process substitution
$ grep -f <(echo hello) file-a
hello
# use pipe
$ echo hello | xargs -I{} grep {} file-a
hello
And for commands like diff <(echo a) <(echo b), it’s not easy to be done by pipe.
More Examples
$ paste <(echo hello) <(echo world)
hello world
How it works
From man bash,
Process substitution is supported on systems that support named pipes (FIFOs) or the /dev/fd method of naming open files.
Read more about named pipe and /dev/fd.
For /dev/fd,
The main use of the /dev/fd files is from the shell. It allows programs that use pathname arguments to handle standard input and standard output in the same manner as other pathnames.
In my OS (Ubuntu), the Bash uses /dev/fd for process substitution.
$ ls -l <(echo .)
lr-x------ 1 user user 64 12月 19 11:19 /dev/fd/63 -> pipe:[4926830]
Bash replaces <(echo .) with /dev/fd/63.
The above command is like ls -l /dev/fd/63.
Or find the backing file via,
$ echo <(true)
/dev/fd/63
(After my Bash does the substitution, the command becomes echo /dev/fd/63,
which outputs /dev/fd/63.)